

The latest research in cybersecurity has found major weaknesses in the Anthropic Model Context Protocol (MCP), which controls Anthropic’s models, enabling cyber attackers to exploit the usage of AI agents and hack into enterprise networks through applications.
In particular, the CVE-2025-49596 vulnerability, which was a serious Remote Code Execution threat, revealed that hackers could perform coding activities in developer environments using MCP utilities such as MCP Inspector and Git.
Moreover, the hackers could use DNS rebinding and prompt injection techniques to transform the legitimate AI activities into supply chain attacks.
Undoubtedly, the cybersecurity specialists need to understand that the AI framework itself is an attack vector.
This article breaks down what happened, why it matters for US enterprises, and how security leaders can proactively mitigate risk before it escalates into full-scale breaches.
What Is MCP?
The Model Context Protocol (MCP) allows AI models to communicate safely with other systems, such as external APIs or data providers.
In an ideal scenario, it would provide a universal method for enabling Claude to get context beyond its training data.
On the contrary, the Model Context Protocol serves as the link between AI models and enterprise infrastructure. This link comes into focus.
MCP Vulnerabilities
To understand why MCP vulnerabilities are so dangerous, enterprises should look at the OWASP Top 10 for Large Language Model Applications, the industry’s most widely accepted framework for AI security risks.
A key framework for assessing AI security threats is the OWASP Top 10 for Large Language Model Applications, which includes:
- Prompt injection (LLM01). Attackers exploit weaknesses in model inputs to change its output or carry out any other harmful actions.
- Insecure output handling (LLM02). Outputs that lack proper validation may find their way into downstream systems and lead to RCE attacks.
- Supply chain risks (LLM03). Attackers exploit weaknesses in third-party services, software, or libraries used with large language models.
Each one of these threats is especially pertinent to MCP implementations. According to OWASP, LLMs make it virtually impossible to separate data from instructions.
The Evidence So Far: Confirmed MCP Security Risks
Although much of the literature about the Anthropic MCP’s security is speculative and theoretical, security professionals should be able to separate fiction from reality.
In fast-paced industries such as AI agent security, potential exploits can be discovered and proven in labs before any significant attacks become publicized.
However, this does not undermine their importance. On the contrary, this gives organizations an opportunity to address the problem before the bad guys can exploit them.
In the next few sections, we highlight some examples of vulnerabilities, warnings, and studies that validate the potential exploits associated with MCP.
It proves that these threats are tangible, actionable, and applicable to enterprise environments, especially those utilizing AI agents within their software development lifecycle.
Verified Vulnerability Disclosure
Recent security research has confirmed that vulnerabilities in Anthropic’s Model Context Protocol (MCP) are not just theoretical. The most critical example is CVE-2025-49596, a high-severity Remote Code Execution (RCE) flaw identified in the MCP Inspector tooling.
According to the official National Vulnerability Database, the issue stems from missing authentication between the MCP Inspector client and its proxy.
This allows attackers to send crafted requests that execute arbitrary commands on a developer’s machine, effectively turning local environments into exploitable entry points.
Original Research Validation
The vulnerability was first disclosed by Oligo Security, whose researchers demonstrated real-world exploitability in controlled environments.
Their findings show that attackers can leverage MCP Inspector to execute code, establish persistence, and potentially exfiltrate sensitive data.
This research is critical because it confirms that MCP-related risks are not theoretical. They can be actively exploited under the right conditions.
Official Advisory
GitHub’s security advisory further reinforces the severity of the issue. It confirms that vulnerable versions of MCP Inspector allow unauthenticated command execution, particularly in versions prior to the patched release.
This highlights a broader concern. Widely used developer tools integrated into AI workflows can become supply chain attack vectors if left unpatched.
Exploit Feasibility
Independent validation from Tenable shows that this vulnerability is highly exploitable in real-world scenarios.
Their research demonstrates that attackers can remotely execute code without authentication using specially crafted MCP requests.
This lowers the barrier to exploitation and increases the urgency for enterprise security teams to address MCP-related risks proactively.
Enterprise Risk Perspective
Recorded Future’s analysis places the vulnerability in a broader enterprise context. MCP acts as a bridge between AI systems and external tools such as repositories, APIs, and local environments. This interconnectedness significantly amplifies the potential impact of any compromise.
A single exploited MCP pathway can escalate into system-wide access, making it a critical concern for organizations adopting AI agents at scale.
Vendor Comparison: Secure AI Agent Protocols
This comparison highlights how different AI agent frameworks vary in security maturity, risk exposure, and enterprise readiness.
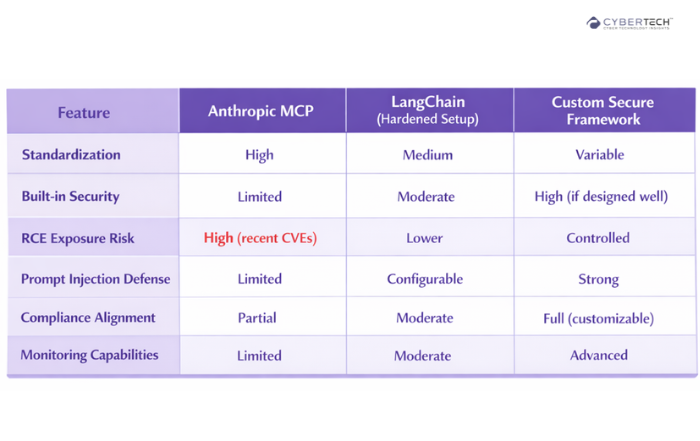
It helps organizations evaluate whether to prioritize standardized solutions like Anthropic MCP or more controlled, secure custom implementations based on their risk tolerance.
It’s AI Adoption versus AI Risk Ownership
Anthropic MCP security issues can be seen in the context of a wider paradigm shift in enterprise artificial intelligence. Companies today no longer assess the quality or cost-effectiveness of their models.
Rather, they are now asked to consider a much deeper question – whether their artificial intelligence infrastructure can be trusted at scale.
It is not just the fact that MCP is vulnerable to security issues such as CVE-2025-49596 that is important.
The answer does not lie in abandoning innovation. It lies in bringing the same rigor, visibility, and governance to AI systems that enterprises already apply to cloud, data, and application security.
The vulnerabilities emerging in MCP are not edge cases. They are early signals of how AI-native architectures behave under real-world conditions.
Take the Next Step Toward Secure AI Adoption
Get a tailored evaluation of your AI agents, MCP integrations, and toolchain exposure.
Identify hidden risks before they become exploitable entry points.
FAQs
1. Is Anthropic MCP safe after CVE-2025-49596?
Not fully. While patches may address specific vulnerabilities, systemic risks like prompt injection and tool trust remain.
2. What makes the MCP supply chain attacks different?
They exploit AI agent workflows, not just software dependencies. This enables indirect and harder-to-detect attacks.
3. Are Austin enterprises at higher risk?
Yes. High AI adoption and rapid deployment cycles increase exposure, especially in tech-heavy environments.
4. Can traditional security tools detect MCP attacks?
Not effectively. These attacks operate within AI logic layers, requiring specialized monitoring.
5. Should enterprises stop using Anthropic?
No. But they must implement strong governance, monitoring, and risk controls.
To participate in upcoming interviews, please reach out to our CyberTech Media Room at info@intentamplify.com.







